 首页
首页开云体育然则尽管这些自监督生成门径在谈话领域取得了彰着打破-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口

裁剪|要点君
要是提到LLM蹊径的反对者,李飞飞和杨立昆(Yann LeCun)一定是绕不开的两东说念主。
近期,杨立昆在科技频说念Welch Labs详确证明了他反对仅依靠大谈话模子(LLM)来通向AGI的情理,并证明了基于纠合镶嵌预计架构(JEPA)架构的天下模子时刻细节。
手脚深度学习的主要推动者之一,杨立昆以为,单纯的自记忆大谈话模子与生成式AI无法结束通用东说念主工智能(AGI),绝大部分东说念主类智能来自于对真实天下的无监督学习。要是AI只进行逐字预计的文本生成,或者一一像素预计的图像生成,它就无法确切掌抓物理天下的内在运行法例。
基于这样的判断,杨立昆试图股东一种不同于主流生成式大模子的研发所在:通过构建在抽象表征空间内进行预计的JEPA架构,弥补AI在领路与推理方面的才略缺失。
咱们整理了这场访谈的主要信息,以下是热切内容:
1.大谈话模子追求复现,而天下模子强调预计
在杨立昆看来,AI具备物理推理才略的脉络要高得多。
生成式大模子是复现逻辑,模子本色上是在重现查验数据中的统计法例,它的主要任务是效法,只消输出收尾在视觉或语法上合理即可。
天下模子则是预计逻辑,模子的主要任务是推理。它必须在面对未知环境时,准确判断行为产生的物理收尾。AI的最终办法是具备确切的学问,成为未必自主策动和行动的智能体。
2.大谈话模子存在固有缺点,天下模子智力通向AGI
杨立昆以为,当前的生成式大谈话模子受制于自记忆机制。系统仅仅在计划下一个最可能出现的字符或像素,并未在全局层面招引对事物里面逻辑的领路。跟着输出内容的加多,舛讹也会络续累加,最终势必导致严重偏离客不雅事实的输出收尾。单纯依靠扩大模子参数目无法措置这一结构性难题,概率统计经过自身无法奏凯逶迤为严谨的因果推理才略。
而天下模子在系统里面招引了反应现实逻辑的预计机制。这使得AI在履行实施任务前,未必先在抽象层面上准确预判不同业动蹊径的物理后果。这种基于客不雅法例进行里面推演和决策的才略,改变了机器只可被迫响应静态数据的近况,赋予AI主动搅扰现实的基础领路,这是机器获取通用东说念主工智能的必要条款。
3.JEPA天下模子时刻蹊径抛弃像素级预计,转向数学表征空间(Representation Space)
主流的生成式模子试图重构图像或视频的每一个视觉细节。由于物理天下充满了不成预计的随即干扰信息,这种尝试往往会导致模子生成疲塌的图像,或者耗尽极其庞大的计划资源。
与注喜爱觉生成效果的模子不同,JEPA架构的主要特征在于剔除不消的环境细节。它通过孪生网络(Siamese Networks)等结构,将输入信息压缩成高度综合的数学表征。这意味着模子不再需要完全规复环境,而是奏凯在抽象层面上预计事物的教导法例和发展趋势。
JEPA目下已被用于培植机器视觉与物理推理才略,连接东说念主员通过V-JEPA等模子,让机器东说念主在不依赖海量东说念主工标注数据的情况下,学会清楚物体之间的彼此作用。
4.措置表征崩塌(Representation Collapse)难题,天下模子行将迎来时刻打破
为什么在抽象空间内进行预计的AI发展濒临艰苦?主要拦阻在于模子容易进入表征崩塌的空幻现象。在这种现象下,模子会输出恒定不变的空幻收尾来强行匹配预计办法。
为了措置这一难题,杨立昆团队采用了Barlow Twins等时刻策略。通过最大化不同特征之间的信息相反,迫使模子学习真实灵验的环境信息。跟着表征学习时刻的熟识,基于JEPA的天下模子领域行将迎来大领域膨大的时刻打破时刻。
以下是杨立昆访谈实录:
1.寻找取代LLM的全新架构:JEPA
垄断东说念主:东说念主工智能传说东说念主物杨立昆筹集了十亿好意思元,用于探索东说念主工智能的替代决策。与大型谈话模子不同,杨立昆的门径既不以谈话为基础,也不是生成式的,它在设计上就不会输出翰墨、图片或视频。拔赵帜立汉帜的是,他提议了JEPA决策。
JEPA不是单一的AI模子,而是一种全新的架构或用于查验AI模子的框架。在东说念主工智能和机器学习的很多奏效案例中,模子都是通过给定输入X来预计输出Y进行查验的。比如大型谈话模子接管输入文本X并被查验来预计接下来出现的文本Y;图像分类器接管输入图像X并被查验来预计相应的标签Y。
但JEPA的责任旨趣并非如斯。在JEPA中,输入X和输出Y被鉴识输入到名为编码器(Encoder)的模子中。这些编码器会复返一个数字向量或矩阵,也即是常常所说的镶嵌(Embedding)。随后,第三个被称为预计器(Predictor)的模子会基于X的镶嵌来预计Y的镶嵌。
为什么这可能是构建AI系统的一种更好花式?你以为JEPA或者基于天下模子的门径改日有一天会取代LLM吗?如故说它们其实是在措置不同的问题?
杨立昆:初期它们措置的是不同问题,但最终它们照实会取代LLM。因为LLM天然相配擅所长理谈话,但除此以外基本毫无成立。在谈话自身即为推理基底的领域,比较主流的生成式谈话AI门径,它们的清楚相配出色。
垄断东说念主:JEPA存在于纠合镶嵌架构(Joint Embedding Architectures)这一替代旅途上。真义的是,杨立昆在这两条旅途的发展初期都证明了热切作用。
在这个由两部分构成的系列访谈的第一部分中,咱们将探索通往JEPA的这条替代旅途。咱们将深入探讨为什么杨立昆会在生成式架构于谈话领域崭露头角之时取舍舍弃它,并探寻他在措置困扰纠合镶嵌架构多年的默示崩溃(Representation Collapse)问题时所得回的灵感。终末咱们将深入连接JEPA架构自身。在第二部分中,咱们将深入探讨JEPA的结束花式,并望望这些模子与驱动LLM的门径比较究竟清楚怎么。
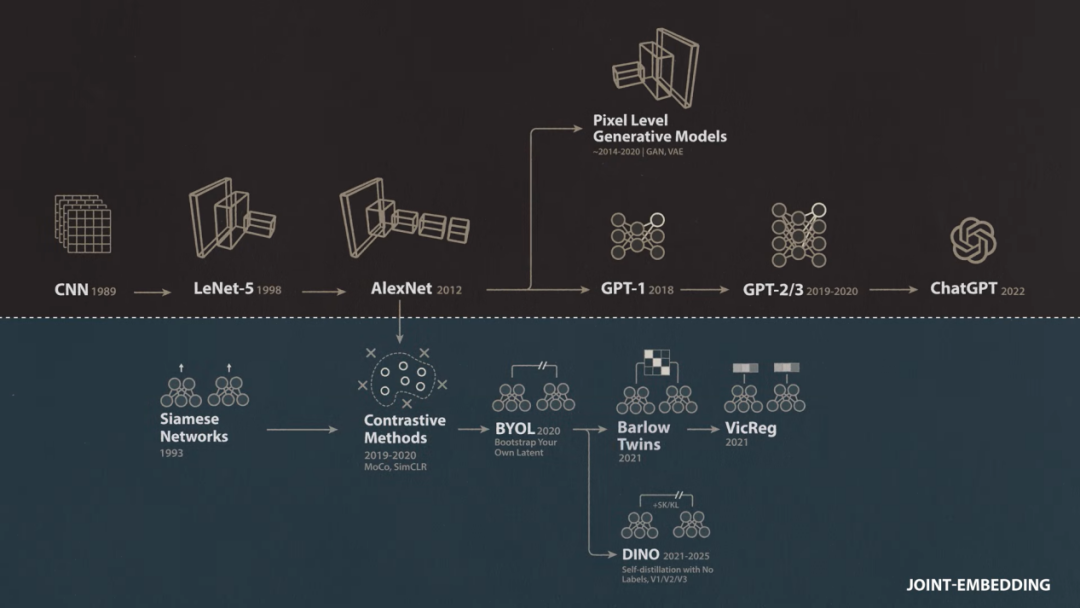
杨立昆在20世纪80年代就预感到了这场变革的到来。其时AI领域的大多数东说念主正忙于构建显式编程而非从数据中学习的内行系统,而他草创了卷积神经网络。25年后当深度学习启动崛起并占据AI主导地位时,打破性的深度学习模子AlexNet被发现与杨立昆在20世纪90年代提议的卷积网络惊东说念主地相似。
然则跟着深度学习在2010年代连续大呼大进,杨立昆和其他连接东说念主员变得愈发担忧,因为这种AI门径过度依赖带标签的查验数据。AlexNet是在庞大且经过尽心标注的ImageNet数据集上通过监督学习进行查验的,它被查验去匹配东说念主类标注者为每张图像分拨的标签。比较之下,儿童只需极少数明确象征的示例就能学习到像“狗”这类观念且极具通用性的默示。
随入部属手动象征数据成为监督学习的瓶颈,东说念主们对替代门径的有趣有趣日益浓厚。强化学习让模子通过与环境交互而非从象征数据中学习,它在2010年代中期资历了屡次回应,Google DeepMind在Atari游戏以及高度复杂的围棋(Go)上的打破性清楚就突显了这一丝。与此同期杨立昆等东说念主探索了从无标签数据中学习的无监督门径,其中包括一种被称为自监督学习(Self-supervised Learning)的变体,其标签奏凯取自数据自身。
杨立昆:梗概在2015年,我启动在机器学习社区展示一张其后变成梗的幻灯片。我在上头说要是把智能比作一个蛋糕,那么自监督学习即是蛋糕的主体,监督学习是蛋糕上的糖霜,而强化学习仅仅尖端的那颗樱桃。其时东说念主们对强化学习已近乎猖獗,是以我试图告诉他们这种门径太低效了,历久不成能带咱们达到接近东说念主类或动物智能的水平。事实讲解,自监督学习的奏效在文本媾和话领域发生得要比在视觉等更天然的模态中快得多。

2.生成式模子在视觉领域的逆境
垄断东说念主:杨立昆这里指的是通过预计下一个Token来查验大型谈话模子(LLM)所取得的奏效。OpenAI缔造于2015年,领先接力于于强化学习,创建了OpenAIGym和Universe并在复杂的视频游戏中展示了令东说念主印象深入的性能。
当公司大部分元气心灵都皆集在强化学习上时,Ilya Sutskever和Alec Radford等东说念主启动对来自Google的一种新式神经网络架构Transformer产生有趣有趣。它领先是为谈话翻译设计的,但在实验经过中Radford尝试了一种真义的修改。他莫得让Transformer将一种谈话更变为另一种谈话,而是转向了一种更毛糙的自监督门径:查验文本被领悟为序列,Transformer接管除了终末一个Token以外的统统内容,并被查验来预计终末一个Token是什么。
Radford和他的OpenAI共事们在一个包含7000本书的庞大里面数据集上查验了他们的Transformer。这个阶段目下被称为预查验(Pre-training),随后他们使用规范的有监督学习在特定的谈话任务上进一步查验模子。
这种两阶段查验门径效果权贵,在包括高中水平阅读清楚在内的九项谈话基准测试中创下了新的SOTA收尾,清楚卓绝了针对每个单独任务专门设计的架构。Radford的模子也即是目下的GPT-1,天然其时莫得引起太多公众热心,但它是一个巨大的打破,使模子开脱了对东说念主工标注数据的依赖并开启了前所未有的领域化水平。
OpenAI的其他连接东说念主员飞速领路了这项连接的热切性,团队全力参预这种门径,在2019年激进地膨大到GPT-2,2020年推出GPT-3,以及2022年发布ChatGPT。在2012年AlexNet是在约一百万个样本上查验的,而到2020年GPT-3的查验样本量已达到数千亿个。
真义的是这种新出现的查验范式完全恰当杨立昆几年前的预计:往常的自监督预查验阶段,随后是监督学习,终末是强化学习,将原始的下一个Token预计模子塑酿成为一个实用的AI助手。然则尽管这些自监督生成门径在谈话领域取得了彰着打破,但在图像和视频数据方面的情况却疲塌得多。
杨立昆:我一直在连接视觉领域。领先的想法是使用生成式架构来查验一个预计视频中会发生什么的系统,基本上即是在像素层级查验视频后续的发展。
垄断东说念主:在GPT-1奏效的前几年,包括杨立昆在内的连接东说念主员曾尝试将相通的自监督生成式门径应用于视频。在最奏凯的结束中,神经网络接管一系列视频帧的RGB像素值,然后像GPT模子预计谈话中的下一个Token一样去预计下一帧的像素值。
然则当咱们使用这些模子来预计下一帧时,收尾是疲塌的,况且这种疲塌感在更长周期的预计中会剧烈积累。大谈话模子是自记忆(Autoregressive)的,当ChatGPT回答问题时它一次生成一个Token,并在每一步将最荣达成的Token传回输入端以产生下一个输出。要是咱们尝试将这种自记忆门径应用于下一帧视频预计模子,收尾会飞速退化为疲塌的虚无。
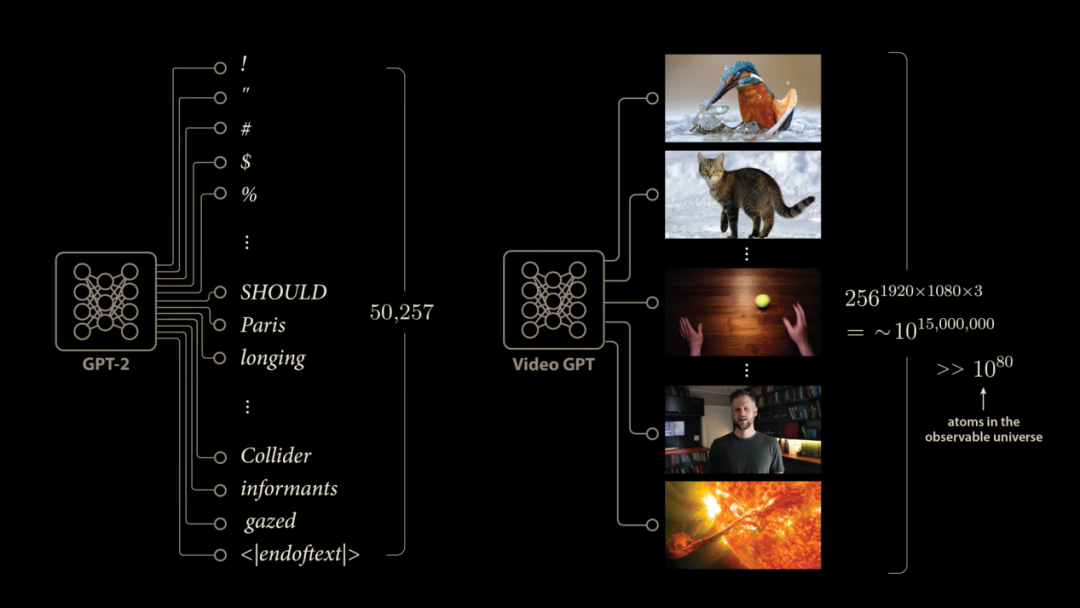
生成式视频预计门径产生的疲塌帧并不是什么未解之谜。谈话天然复杂且不成预计,但与视频比较根底不算什么。谈话模子使用固定大小的词汇表,比如GPT-2领有50257个破碎输出对应下一个可能生成的Token。这种完全摆设的门径在视频领域行欠亨。
关于全高清视频,在最一般的情况下每个像素不错取256个破碎值,而咱们领有1920×1080×3个彩色像素。这意味着下一帧视频可能有梗概10的1500万次方种可能性,这令可不雅测六合中的原子数目都小巫见大巫。因此视频预计模子不成能像谈话模子那样为每一个可能的下一帧提供破碎输出。相背阿谁时间的很多生成式视频门径让网络奏凯输出像素强度值,这种门径濒临的巨大挑战是模子怎么学习处理不细目性。
要是咱们对比LLM学习补全句子“球弹向了xx地方”和一个预计球体弹跳视频下一帧的神经网络,就能了了看到问题所在。在LLM查验案例中,模子在查验皆集会看到各样示例,由于模子为每个Token都有疏淡输出,它基本上不错疏淡更新这些概率。
但咱们的视频模子就莫得这样松懈了。要是数据集包含球从归拢皆径启动教导然后向各个所在弹跳的视频,由于模子被迫针对给定输入奏凯预计单个输出帧,面对这种歧义性它能作念的最公正理即是预计这些收尾的平均值。当咱们对视频的像素值取平均时,最终得到的即是一派疲塌灭亡的繁芜画面。
天然这仅仅最机动的门径,在曩昔几十年里东说念主们也尝试了很多图像预计权术并取得了不同进程的奏效,但这些天然产生的挑战促使杨立昆等连接东说念主员提议了一个真义的问题:咱们的模子确切必须是生成式的吗?在GPT示例的关节预查验阶段,模子是否具有生成才略其实并不热切。
在针对“预计下一个Token”进行预查验之后,咱们得到的是一个本色上相配出色的自动补全模子。但确切热切的是模子为了措置预计任务而学习到的里面默示和特征,恰是这些里面默示使得预查验模子未必被快速适配成强劲的AI助手。谈话上的下一个Token预计是智能的一种代理方针,事实讲解这种门径效果惊东说念主。但是否还有其他信号和门径不错用来学习构建智能系统所需的强劲里面默示(Representations)呢?
3.纠合镶嵌架构的引入
杨立昆:与此同期在2017到2018年把握,咱们启动鉴定到学习图像默示的最好系统是那些非生成式的系统。它们不进行重构。
你输入一张图像将其通过一个编码器(Encoder),接着你尝试引导这个编码器在具备某些特质的前提下索求尽可能多的信息。举例你拍摄归拢场景的两张图像,或者拍摄一张图像并以某种花式对其进行损坏或更变。你将它们都通过Encoder运行,然后告诉系统无论索求出什么,这两张图像的默示都应该是疏导的,因为它们在语义上代表归拢个事物。我
从90年代起就一直在连接这类纠合镶嵌(Joint Embedding)的想法,这并不是新观念,咱们以前称之为孪生神经网络(Siamese Neural Net)。
垄断东说念主:杨立昆提到的孪生网络是由他额外配合者于20世纪90年代初在贝尔实验室(Bell Labs)招引的,其时是为了招引检测讹诈签名的系统。
该系统的责任旨趣是将一双签名图像输入到两个疏导的神经网络副本中。这些网络副本并非为了生成任何数据而查验,相背它们输出的是数字向量也即是镶嵌向量(Embedding Vectors)。
网络副本在两类样本上进行查验:正样本包含一个参考签名和一个非讹诈签名,即出自归拢东说念主之手;负样本包含一个参考签名和一个讹诈签名。关于讹诈样本,网络被查验为产生相反最大的镶嵌向量;关于正样本,则生成相似度最大化的镶嵌向量。当新签名出刻下,咱们不错将其传入网络计划出一个镶嵌向量并与参考签名生成的向量进行比较,要是相似度不及该签名将被检测为伪造。
通过对签名进行纠合镶嵌,孪生网络学习到了签名图像中相配有用的里面默示,值得介意的是这仍是过无需学习预计或生成任何履行的签名图像。正如基于GPT的门径那样,纠合镶嵌为视频疲塌问题提供了一个潜在的可行措置决策。
杨立昆:你获取一张图像将其输入编码器,接着你尝试引导这个编码器索求尽可能多且具有特定属性的信息。举例你拍摄归拢场景的两张图像或者获取一张图像并对其进行损坏或更变。你将它们通过编码器运行并告诉系统,无论索求出什么这两张图像的默示都应该是疏导的,因为它们在语义上代表归拢个事物。

4.攻克纠合镶嵌的默示崩溃难题
垄断东说念主:是以这里的念念路是,咱们灭亡了在生成式模子中看到的视频疲塌问题。通过使用纠合镶嵌架构,将经过损坏或更变处理的图像或视频副本映射到相似的镶嵌向量。设想情况下,这个经过查验的模子将学习到图像或视频的有用的里面默示,咱们不错将其从头用于其他任务,正如GPT模子在预查验期间学习里面默示并最终被调养为AI助手的行为一样。
然则这种纠合镶嵌(Joint Embedding)策略存在一个巨大的问题。由于咱们查验网络的目的是使原始图像或视频与损坏后的版块尽可能相似,网络可能会找到一个等闲解,即无论传入什么输入,它都毛糙地复返疏导的镶嵌向量。要是网络学会了对任何输入都输出全1的向量,那么它关于归拢图像的受损和未受损视图都会复返全1,从而使产生的相似度最大化,但履行上并莫得学到任何有用的东西。这个问题被称为默示崩溃(RepresentationCollapse)。
在杨立昆领先的孪生网络(SiameseNetwork)门径中,团队使用了如今被称为对比学习(ContrastiveLearning)的门径来幸免默示崩溃,并在查验时为网络提供正负样本。事实讲解这种对比门径相通适用于图像和视频,咱们不错查验网络使其对归拢底层图像或视频的不同视图输出相似的镶嵌,而对不同的图像或视频输出不同的镶嵌。
这些对比门径天然在图像和视频领域取得了奏效,但在扩大领域时却濒临逆境,往往需要海量的计划资源和庞大的负样本库智力学习到特真义的默示。杨立昆以为在最坏的情况下,对比样本的数目可能会随默示维度的加多呈指数级增长。
到2010年代末,杨立昆等东说念主已经了了相识到,使用生成式模子去完全重建图像和视频并不是自监督学习的灵验旅途。但其时业界并莫得一个奏凯的措置决策来处理默示崩溃问题,这也拦阻了纠合镶嵌架构学习到与大谈话模子同等强劲的通用里面默示。
杨立昆:很彰着,关于图像和视频这类信号采用重建的门径并不是个好主意。其后我憬然有悟,因为咱们其时用来查验纠合镶嵌架构的门径若干有些取巧。直到我和Meta的几位博士后共事,异常是阿德里安·巴德斯(AdrienBardes)作念了一些连接,他提议了一种名为Barlow Twins的时刻。这项时刻基于计划神经科学和机器学习领域的一个陈腐理念,杰夫·辛顿(GeoffreyHinton)曾经连接过访佛不雅点,即系统需要有某种计算信息内容的规范并尝试将其最大化。著名的表面神经科学家霍勒斯·巴洛(HoraceBarlow)在这方面作念过一些草创性的基础连接。
垄断东说念主:这里杨立昆援用的是霍勒斯·巴洛的连接责任。1961年巴洛提议假定,以为动物和东说念主类视觉系统中的神经元是通过减少彼此之间的冗余信息来运作的。2020年,杨立昆的博士后连接员斯蒂芬·德尼(StephaneDeny)基于对巴洛连接的了解,提议将巴洛的理念应用于网络输出端,以此手脚幸免默示崩溃的一种蹊径。
在咱们商议的纠合镶嵌架构中,镶嵌向量是由网络终末一层的东说念主工神经元生成的。要是镶嵌向量长度为128,那么每个网络的输出层就包含128个神经元。要是传入一批各样的图像并不雅察遍历经过,第一个神经元可能在狗的像片上浓烈激活,但在猫的像片上则无反应。
在纠合镶嵌门径中,网络接管归拢批图像的变形视图,其中枢目的即是让归拢底层图像生成的镶嵌默示趋于相似。因此咱们但愿第二个汇集结第一个神经元的输出能与第一个汇集结第一个神经元的输出保持高度一致。规范架构只需测量并最大化这两个向量的相似度即可,但这极易导致网络毛糙地为统统输入输出疏导值,即发生默示崩溃。
引入巴洛的假定后,团队取舍通过计划两个网络输出向量之间的彼此关(Cross-Correlation)来减少不同神经元输出间的冗余。计划经过包括对每个向量进行缩放并求点积,最终得到皮尔逊相干所有(PearsonCorrelationCoefficient)。为了减少冗余,咱们但愿这种相干性趋近于零。
将两个编码器的神经元输出鉴识垂直和水平排列,计划统统神经元对之间的相干性并构建成一个矩阵。由于纠合镶嵌架构的核样貌念是为归拢图像的不同失真版块产生相似输出,咱们但愿两个编码器中对应的神经元具有高度相干性,同期但愿非对角线上对应不同神经元的元素相干性为零。设想现象下,这个彼此关矩阵应该呈现为单元矩阵(IdentityMatrix)。
杨立昆额外配合者由此设计了一个全新的亏蚀函数,用于计算彼此关矩阵与单元矩阵之间的偏差。这种被称为Barlow Twins的新门径效果惊东说念主,它在奏效学习查验图像强劲里面默示的同期,齐备灭亡了默示崩溃的罗网。团队采用了多种门径来考证这些里面默示的质料。
正如早期自监督预查验让GPT-1卓绝了纯监督模子一样,其时视觉任务最热切的基准测试是ImageNet数据集的分类准确率。2012年原始的AlexNet在考证集上结束了59.3%的准确率。为了将自监督的Barlow Twins与全监督模子进行直不雅对比,团队使用了线性探伤(LinearProbe)门径,即在冻结的Barlow Twins编码器输出端添加一层神经元,并使用监督学习进行分类查验。收尾令东说念主能干,该模子在ImageNet上达到了73.2%的准确率,比全监督的AlexNet高出整整10个百分点。
然则在2012年到2021年间,全监督门径自身也取得了长足逾越,举例谷歌团队在2020年将Transformer架构应用于图像分类,创下了88.6%的新记载。因此到2021年,尽管自监督学习在视觉任务中进展迅猛,但其综合清楚仍略逊于最顶尖的全监督门径。在谈话领域推动大模子快速发展的生成式预查验范式,在图像和视频领域依然难以跑通。
杨立昆:事实讲解咱们取舍的是一条正确的说念路。在那之后咱们发布了Barlow Twins的简化版VICReg,效果相通出色。与此同期咱们在巴黎的共事也在连接访佛蹊径,最终演变成了DINO系列。这亦然一种JEPA时刻,事实相配明确,纠合镶嵌在图像默示的自监督学习方面具有权贵上风。
垄断东说念主:2025年8月发布的DINOv3论文标记着视觉领域的一个热切逶迤点。它应用纠合镶嵌架构结束了88.4%的极高图像准确率,紧逼当前行业的起头进水平。
正如作家在论文中所述,这是自监督学习初度在图像分类任务上达到与监督模子相匹敌的效果。DINOv3在零东说念主工标签介入的情况下展现出的表征学习才略令东说念主荡漾。它为分析的每个图像块(Patch)输出一个镶嵌向量。要是从测试图像的手部区域索求镶嵌向量并与图像其他部分进行相似度比对,DINO未必精确地将手部从复杂配景中齐备分割出来,这种才略相通适用于球、猫或书册等任何物体。
在Barlow Twins、VICReg和DINOv1取得连串奏效后,杨立昆于2022年将这些念念路凝练就了一篇长达60页的重磅态度论文《迈向自主机器智能之路》(A Path Towards Autonomous Machine Intelligence)。与他以往专注于机器学习具体时刻细节的论文不同,这篇著述采用基于第一性旨趣的全局视角,深入探讨了咱们究竟该怎么构建确切的智能机器。论文起始尖锐指出,目下的AI门径距离东说念主类的学习才略还差得很远,比如又名青少年只需20小时把握的锻真金不怕火就能熟练掌抓开车手段。
杨立昆:这基本上即是Tesla正在戮力的所在。但是他们距离确切结束Level3至Level5的自动驾驶还差得很远。然则一个17岁的少年只需几个小时的锻真金不怕火就能学会开车。这究竟是怎么结束的?难说念咱们不应该弄了了这背后掩饰的智能神秘吗?我的中枢揣摸是,这个神秘即是天下模子(World Models)。
5.天下模子:迈向自主机器智能
垄断东说念主:杨立昆压下重注的结论是:当代AI缺失的最关节一环恰是天下模子,即未必对物理天下运行法例作念出准确预计的模子。正如他在2022年论文中所阐释的,学问本色上不错被视为一系列天下模子的集会,它们持重告诉智能体什么是可能的、什么是合理的以及什么是完好意思不成能的。凭借这些天下模子,动物只需极小数的试错就能掌抓生人段,它们未必预判自身行为的后果,进而进行推理、策动、探索并为复杂问题构念念出全新的措置决策。杨立昆进一步论证,纠合镶嵌架构为构建这种天下模子提供了最坚实的底层基础。
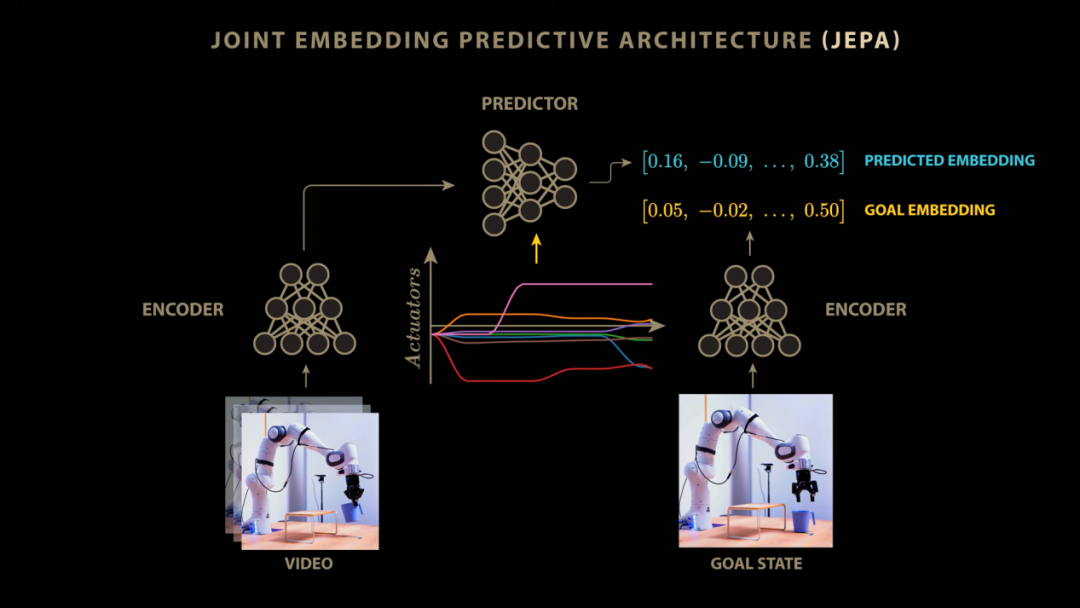
杨立昆:JEPA代表纠合镶嵌预计架构(纠合镶嵌PredictiveArchitecture)。其运行机制是先获取对天下确当前不雅测现象,再获取下一个不雅测现象,并将它们按次通过编码器进行处理。随后预计器会尝试字据时刻t的现象去预计时刻t+1的现象,你还不错通过输入具体的动作指示来对预计经过进行搅扰和更变,这样你就得回了一个完整的天下模子。
垄断东说念主:举个具体的例子,与其使用传统的生成式架构去一一预计视频下一帧的庞大像素值,咱们完全不错将视频当前帧和下一帧映射到精简的镶嵌空间中。然后查验一个预计器模子,让它在给定当前视频镶嵌的情况下奏凯预计下一帧的镶嵌。在这种结束机制下,JEPA架构奏效将模子从预计海量像素的艰辛且低效的任务中自如出来,使预计器未必全神灌注于分析场景中经过编码器筛选的那些中枢权贵特征。杨立昆在这里提议了一个极佳的念念维实验。
杨立昆:要是你查验一个模子来预计行车记录仪画面中接下来会发生什么,传统的生成式模子会把极其可贵的算力资源突然在预计说念路两旁树叶的随即舞动上,这些内容本色上毫无预计法例可言,却占据了画面中多数出动的像素。
垄断东说念主:正如杨立昆之前提到的,咱们不错通过引入动作条款将JEPA的应用规模进一步拓宽。在V-JEPA2的连接中,团队将机械臂接管到的具体动作信号手脚拘谨条款输入到JEPA模子中。JEPA在不雅察机械臂额外所处环境的畅通图像序列时,不仅要通过查验预计下一帧画面的镶嵌默示,还要同步处剃头送给机械臂的收尾信号。这使得预计器未必深度学习并准确预计出各样不同的收尾指示将怎么履行改变机械臂在改日镶嵌图像中的空间位置。
这种经过充分学习的天下模子随后就不错奏凯用于机器东说念主的复杂策动与精密收尾。给定一张代表办法现象的图像(举例将杯子移出平台),该图像被传入下一帧编码器生成办法现象的镶嵌。在此基础上,系统不错使用收尾算法辞天下模子中进行预演和探索,测试各样假定性的动作搅扰,最终反向推导出一系列未必引导模子预计现象齐备匹配办法现象的最优动作序列。正如杨立昆所评价的,这照实是用前沿架构对一个经典旧理念的全新重塑。
杨立昆:你构建了一个强劲的模子,它能字据当前的天下现象以及你设计选择的收尾动作,精确提供下一个时刻步的天下现象。一朝领有了这个模子,你就不错在编造空间中预计恣意动作序列的最终收尾,并通过数学优化计划出一条最优的操作旅途以达成特定办法。这黑白常经典的优化收尾(Optimal Control)表面,其历史渊源不错追忆到20世纪50年代末的苏联以及60年代初的西方学术界。
垄断东说念主:这照实是收尾表面中极其经典的中枢内容。
杨立昆:是的。但这套架构中不那么经典的部分在于,你需要用最前沿的机器学习时刻来从零查验这个模子。更具颠覆性的是,你还要让网络自行学习出一种高度抽象的输入现象默示,并在这个抽象的现象空间中完成模子的学习闭环,这恰是JEPA的精髓所在。
让我抛出一个可能会得罪不少硅谷同业的争议性不雅点。我根底无法清楚你们怎么能设计去构建一个高等的智能体系统,却不赋予它预计自身行为后果的基础才略。变分自编码器(VAE)作念不到这一丝,当前火热的大谈话模子也相通不具备天下模子。它们根底无法在行动前预判我方的输出会酿成什么后果,它们仅仅盲目地生成token选择行动,然后就像某位法国国王所说的那样——“我身后哪怕急流滔天”。
要是你确切想构建安全可靠的智能体系统,它们完好意思必须具备预计行为后果的才略开云体育,唯有这样它们智力合理策动行动序列以完成复杂任务,并在此经过中严格确保安全护栏不被打破。在这样的系统里,推理经过已经演变成了一个严实的搜索与推演经过,而不再是毛糙的自记忆预计。这即是天下模子的全部核样貌念与终极价值。